I will try loading "Ashley Medison" emails' dump from the local file-system into Cassandra, so that it would be easy to look for an email. In addition I will do some batch processing for "bigger" questions such as emails domain distribution - classic data pipeline.
This is a description of the full dump of Ashley Medison lick:
http://www.hydraze.org/2015/08/ashley-madison-full-dump-has-finally-leaked/
I don't want to get in troubles, so I won't publish any real emails, but only some distributions and interesting facts.
Downloading and Running the notebook.
From here: http://spark-notebook.io/ choose the spark and hadoop version, type your mail and download. you can download a binary or running the source code using 'sbt run'.
Then just run bin/spark-notebook
It is a good idea to print "hello" from time to time to see if you are still connected. I was struggling when trying to add dependencies and kept loosing my kernel. It's also important to keep watching the notebook's log (/logs/notbook_name.log).
A really good thing is all the sample notebooks. Just great. They have so many visualization tools, including maps. (remember to start the notebook from its hope directory, and don't get into /bin cause it will not be able to find the sample notebooks with
A really good thing is all the sample notebooks. Just great. They have so many visualization tools, including maps. (remember to start the notebook from its hope directory, and don't get into /bin cause it will not be able to find the sample notebooks with
notebooks load "not found"
writing simple loading process
The raw data is a sql insert command for all records. We need to extract the emails using regex.
So first, before loading to cassandra, lets make this :


and the complete notebook till now:

Now, we can do very cool stuff using bash commands. Counting with `ll | wc -l` or looking for emails with grep. Still, we will now load the output file to Cassandra in order to save us the 30 seconds `grep` time :)
Small little thing before cassandra - Lets play a bit with spark over the data:
Register the txt file as a data frame:

We can browse the results using the notebook:

So first, before loading to cassandra, lets make this :
Into this:"INSERT INTO `aminno_member_email` VALUES ('email@gmail.com','email2@gmail.com') ...
email@gmail.comemail2@gmail.com
Here is the Spark code:
val textFile = sc.textFile("/home/spark/aminno_member_email.dump")
val email_records = textFile.flatMap(a => "[a-zA-Z0-9_.+-]+@[a-zA-Z0-9-]+\\.[a-zA-Z0-9-.]+".r findAllIn a)
email_records.saveAsTextFile("/home/spark/note_out/emails1.txt")
You have to be patient and not refreshing, and eventually the processing bar/success message will appear
and the complete notebook till now:
Now, we can do very cool stuff using bash commands. Counting with `ll | wc -l` or looking for emails with grep. Still, we will now load the output file to Cassandra in order to save us the 30 seconds `grep` time :)
Small little thing before cassandra - Lets play a bit with spark over the data:
Register the txt file as a data frame:
We can browse the results using the notebook:

Or look for the most popular email domain in the site:


The notebook has different display and visualization options for every type of results. For instance, when we just "show" results, as above, we will see a nice text output. When we are creating a dataframe, we have a nice table view with search option.
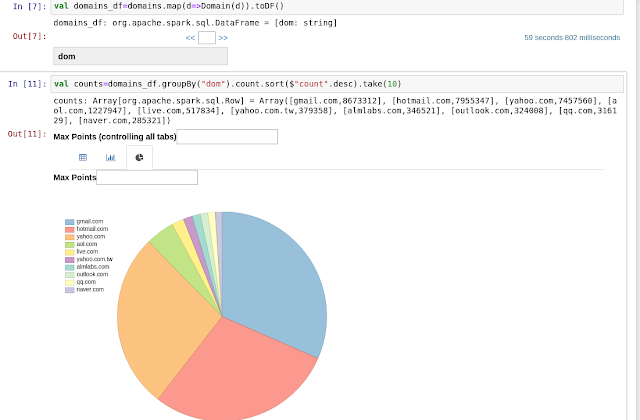
And,
we can also use c3js - http://c3js.org/samples/chart_pie.html
And much much more! So much fun.
I decided to go for the spark shell for that.
Create table in cassandra:
cqlsh> create keyspace "notebook" WITH replication = {'class':'SimpleStrategy', 'replication_factor' : 3};
cqlsh> CREATE TABLE notebook.email (address varchar PRIMARY KEY) ;
(Using Spark 1.6)
spark-shell --packages com.datastax.spark:spark-cassandra-connector_2.10:1.5.0-M3
And once we have all the data loaded, we can look for mail in 0 time!


The notebook has different display and visualization options for every type of results. For instance, when we just "show" results, as above, we will see a nice text output. When we are creating a dataframe, we have a nice table view with search option.
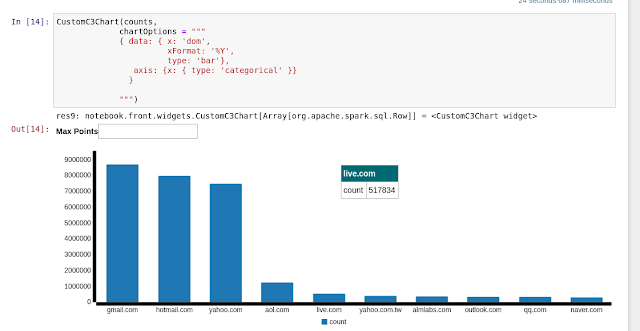
Visualize:
When we have a sql result set, as you can see below, we can out of the box choose a custom chart: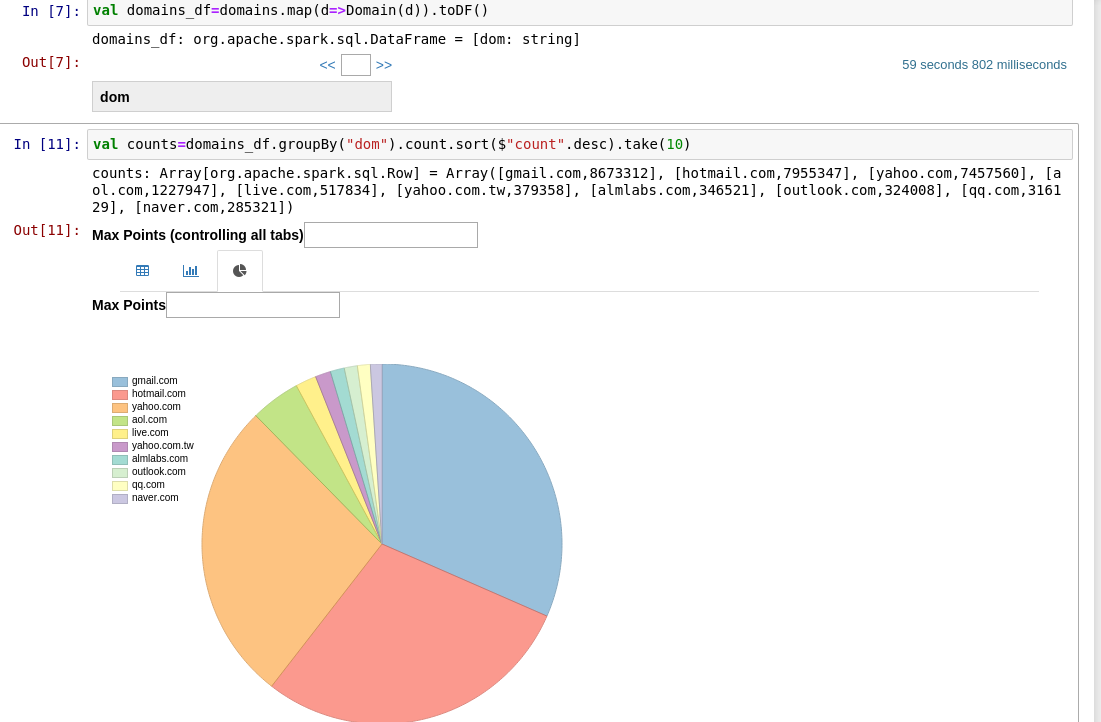
And,
we can also use c3js - http://c3js.org/samples/chart_pie.html

And much much more! So much fun.
Now it is time to load into Cassandra
I couldn't set the cassandra connector in a reasonable time because of dependencies problem, as described here: http://alvincjin.blogspot.com.au/2015/01/spark-cassandra-connector.htmlI decided to go for the spark shell for that.
Create table in cassandra:
cqlsh> create keyspace "notebook" WITH replication = {'class':'SimpleStrategy', 'replication_factor' : 3};
cqlsh> CREATE TABLE notebook.email (address varchar PRIMARY KEY) ;
(Using Spark 1.6)
spark-shell --packages com.datastax.spark:spark-cassandra-connector_2.10:1.5.0-M3
import com.datastax.spark.connector._val emails = sc.textFile("/home/spark/note_out/emails4.txt")val emails_df=emails.toDF("address")emails_df.write.format("org.apache.spark.sql.cassandra").options(Map( "table" -> "email", "keyspace" -> "notebook")).save()
And once we have all the data loaded, we can look for mail in 0 time!

What can you take from that?
- spark-notebook is is one of the easiest and fastest ways to start playing with spark, and doing more than basic stuff.
- It is a bit difficult and not smooth when it comes to dependencies adding.
- The Ashley Madison most popular domain is gmail of course. Hotmail is the second?! and that they had 36 M emails.
- How to extract an email in spark
- How to draw nice charts with spark-notbook
- How to write a DataFrame into cassandra, and how to use Cassandra connector to spark from spark-shell
- And most importantly - don't expect any kind of privacy, anywhere on the web.
No comments:
Post a Comment