Ofer Habushi, a friend of mine, that is working as a senior consultant for Talend (an open source Data Integration Software company),
was asked by one of his customers, a major e-commerce company, to present a solution for aggregating huge files of clickstream data on Hadoop (Ofer’s youtube video).
With a given huge website’s clickstream file (>100 GB or even Teras), Aggregate and create session records for all users (userId) and for all of their clicks which were made within 30 minutes of their previous click on the website
If the user was not active in the last 30 minutes -> create a new sessionID.
Else -> use the same sessionID.
Sample Input:
userID
|
visitStartDate
|
visitEndDate
|
user1
|
26/01/2016 04:48
|
26/01/2016 04:48
|
user1
|
26/01/2016 04:57
|
26/01/2016 04:57
|
user2
|
26/01/2016 04:40
|
26/01/2016 04:40
|
user1
|
26/01/2016 06:57
|
26/01/2016 06:57
|
sample Output:
sessionID
|
userID
|
visitStartDate
|
visitEndDate
|
user1_04:48
|
user1
|
26/01/2016 04:48
|
26/01/2016 04:57
|
user2_04:40
|
user2
|
26/01/2016 04:40
|
26/01/2016 04:40
|
user1_06:57
|
user1
|
26/01/2016 06:57
|
26/01/2016 06:57
|
The company, that was already using an early version of Talend, had already implemented a solution for this problem using a mixture of three different languages in one process. It was a mixture of Talend, Java , Hive with a Hive UDF in Python.
With the coming of Talend v6.X, the company was interested in testing the capabilities of the new Talend Spark job feature.
The goal was defined as following:
- Build the same logic to achieve the same results.
- Reduce the multi language complexity (no udfs)
- Make the job graphical and readable as possible (reduce the code significantly).
- Improve or keep the current performance.
In order to solve that challenge, Ofer decided to use Talend which allows to design Spark jobs. Talend provides a graphical interface that generates, in this case, code based on Spark’s Java API.
Next, we’ll discuss what's needed in Talend and Spark in order to solve the clickstream use case. A use case that leads us to tackle spark shuffle, partitioning, and spark secondary sort.
When Ofer introduced me the story, and asked me to review the Talend and Spark solution, I couldn’t tell if the underlying spark talend job would be similar to the solution that I would come with, writing plain spark.
So I started designing the solution with spark, while asking Ofer, after every step, if Talend supports the method that I am using in the step.
- Partition the data into userId’s partitions, because after having all the clicks of a user at the same partition we can create the users’ sessions in parallel and with no additional shuffles.
- The Spark way - partitionBy(new HashPartitioner(100)) on a key-value rdd
- The Talend way - Ofer found that Talend has a “tPartition” component, that is translated to a Spark “partitionBy”. Step 1 is checked!
- Sort each partition by userId and by event time (secondary sort). This is essential for understanding where a session starts and ends - we are going through the clicks of each user, until we find a click that comes at least 30 minutes after the previous click.
An interesting question is how can we keep the data partitioned and sorted? Think about it - that’s not a simple challenge. When we sort the entire data set, we shuffle in order to get a sorted rdds and create new partitions which are different than the partitions we got from step 1. And what if we will do the opposite? First sort by creation time and then partition? We will encounter the same problem. The re-partitioning will cause shuffle and we will loose the sort. So how can we do that?
Partition → Sort - losing the original partitioning
Sort → Partition - losing the original sort
- The spark way to partition and sort would be to use repartitionAndSortWithinPartitions. This is not too simple.
The secondary sort is based on a composite key of the 2 columns and of a custom partitioner that will only partition by the first column. In this way, we get all the values of each real key sitting within the same partition. Now we get spark to sort all the partition elements by the combined key. With the next method that does both partitioning and sorting, together with a custom partitioner, we don't need step 1 anymore -repartitionAndSortWithinPartitions(partitioner)
The last thing that we need to do is to supply a custom comparator for the combined key because we can’t expect spark to know by itself how to sort the combination of number and date (the tuple is kind of a new type). repartitionAndSortWithinPartitions is defined by: def repartitionAndSortWithinPartitions(partitioner: Partitioner)
So how do we set the comparator? For that we will create a new class that would stand as our combined key, together with an implementation of a custom comparator . You can find here a great example for all of that.
- Talend Way - I thought that there is no chance that Talend would support all of this headache. Ofer made some research and found it all. As we said, Talend has a tPartition component. Fortunately, it supports sorting together with the partitioning with the exact same method that I have used in Spark (repartitionAndSortWithinPartitions).
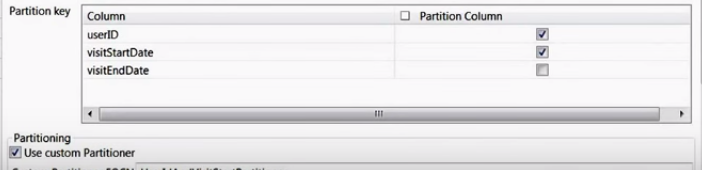
In the above picture you can see Ofer chose a combined partition key and set a custom partitioner. I find Talend easier than just writing spark in that case, because we don’t need to create a dedicated class with a comparator for that secondary sotr. Talend understands what’s the type of the combined key.
3. Creating the sessions - Foreach partition, in parallel, Foreach userId, run over all clicks and create a session field.
In spark it’s a simple fold call with an inner logic. It’s quite the same with talend, that offers a tJavaRow for custom java code that will run after the partitioning+sorting. It would be nice to have a tScalaRow component though (perhaps planned for Talend next release v6.2)
To summarize , Spark is a great platform for this case, having the ability to do distributed aggregation on large amounts of click stream data, create sessions that requires sorting.
Surprisingly (or not?) Talend-Spark integration supports all that’s required and in addition of course, let you enjoy the benefits of a mature and rich ETL tool.
Here is a link to Ofer’s youtube video, telling exactly how to implement the click stream analysis with spark and Talend.
No comments:
Post a Comment